
THE ADVERSARIAL AGENT
HOW THREAT ACTORS EXPLOIT THE NONHUMAN IDENTITY GAP

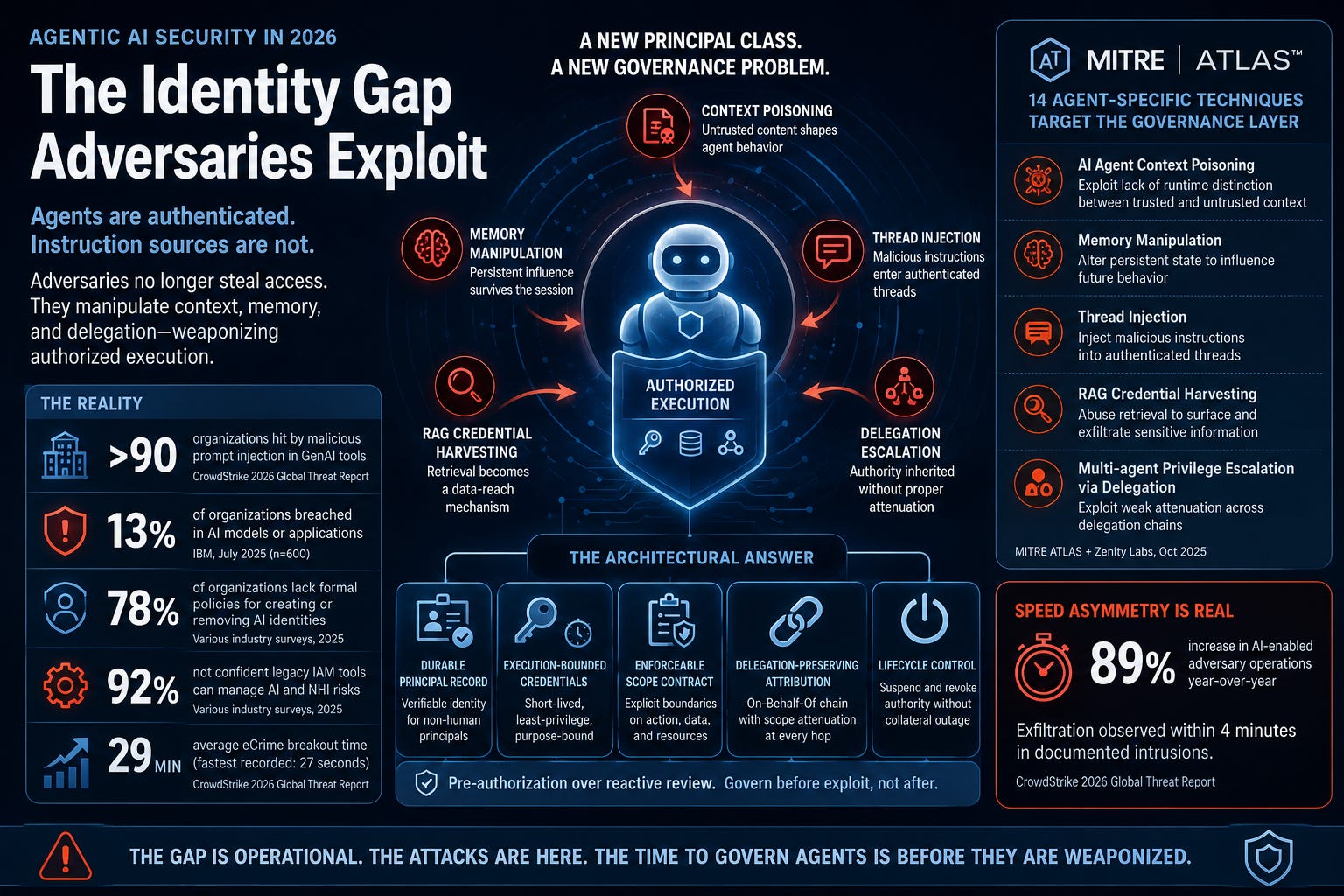
“The attacker does not need to break in if the agent can be redirected in place.”
That is the state of agentic AI security in 2026. It is worth sitting with for a moment, because it describes a structural shift in enterprise threat modeling that most security programs have not yet absorbed.
«»
The Governance Gap Is Already Operational
Today we take a closer look at what it actually means for adversaries when an enterprise deploys agents into production without a governed non-human identity architecture.
The short answer: it means the attacker inherits authorized execution rather than having to steal it.
That is the central claim of the brief, and it is a significant reframe of how most enterprise AI security analysis still approaches this problem. The first generation of agent compromise is not primarily a model-safety story, a jailbreak story, or a content-filtering story. It is an identity and authorization story. When an adversary can alter the instruction stream, the retrieved context, the memory state, or the activation path of an already-authorized agent, the decisive question is no longer whether the model was manipulated in the abstract. It is whether the manipulated model remained authorized to act under the same scope, credential chain, and delegation path after the instruction source changed.
Most current enterprise stacks never ask that question. They authenticate the agent at issuance time and then allow the model to continue planning under the assumption that all instructions entering the context are equally eligible to shape execution, so long as they produce actions within the credentialed boundary.
That is the identity gap. The agent is authenticated. The instruction source is not.
The governance gap this creates is not theoretical. CrowdStrike’s 2026 Global Threat Report documents adversaries actively injecting malicious prompts into GenAI tools at more than 90 organizations. IBM’s July 2025 report found that 13% of organizations had already experienced breaches of AI models or applications; with 97% of those reporting a lack of proper AI access controls at the time of the incident. It’s worth noting IBM’s sample covered 600 organizations, so these are not edge-case numbers.
«»
MITRE ATLAS Makes the Attack Surface Legible
One useful development in the past year is that the attack surface is now taxonomized well enough to actually reason about it systematically.
In October 2025, MITRE ATLAS, working in collaboration with Zenity Labs, expanded the framework with 14 agent-specific techniques and subtechniques, specifically because the existing infrastructure-focused vocabulary was insufficient to describe how agents get compromised. This was not a minor update. It was an acknowledgment that adversaries are already operating against governance surfaces that most detection programs have never modeled.
The techniques matter because each one targets a named identity component, not the model in the abstract. The attached brief maps them precisely:
AI Agent Context Poisoning targets the behavioral envelope; the absence of runtime distinction between authorized task context and adversary-shaped context.
Memory Manipulation targets principal continuity; the absence of provenance control over writes to persistent state.
Thread Injection targets the scope contract; the absence of enforcement boundaries on instructions entering an authenticated thread.
RAG Credential Harvesting targets the credential chain; treating retrieval as a knowledge feature rather than a scoped access surface.
Multi-agent privilege escalation via delegation targets the attribution chain; the absence of scope attenuation at each delegation hop.
The pattern that emerges is not coincidental. These attacks became possible not because AI systems are fragile but because enterprises are deploying a new principal class inside a governance architecture designed for a different kind of actor.
A SOC calibrated exclusively for MITRE ATT&CK has modeled the infrastructure layer. The agent-specific techniques target the governance layer above it. Both are required and they are not the same exercise.
«»
Prompt Injection Is an Authorization Failure
The standard enterprise response to prompt injection is to treat it as a content problem: filter suspicious inputs, detect attempts to override system prompts, screen outputs for prohibited material. Those controls are not useless. They are downstream of the actual failure.
The architectural reason prompt injection works is that agents evaluate semantics before they re-evaluate authority. A retrieved document, an inbound email, a web page, a tool response, and a human task request all arrive in the same model context stream. The model has no native mechanism to cryptographically distinguish trusted instructions from untrusted content. OWASP LLM Top 10 2025 (LLM01) states this directly: language models cannot currently distinguish trusted instructions from untrusted content in any cryptographically meaningful sense. Once the adversary’s instruction reaches the planning layer, the relevant question is no longer whether the sentence looks malicious. It is whether that instruction source is authorized to request the contemplated action from this principal.
This distinction matters operationally. Content filtering evaluates what instructions say. Identity-aware authorization evaluates where instructions came from. Adversary directives embedded in retrieved content are frequently syntactically and semantically normal; they request steps that are individually plausible, within the agent’s scope, and that do not trigger content-based anomaly rules. The sequence is harmful; the individual instructions are not.
The real-world incident record confirms this at production scale. In June 2025, researchers disclosed EchoLeak (CVE-2025-32711), a zero-click vulnerability in Microsoft 365 Copilot. A single crafted email, requiring no user click, caused Copilot to extract sensitive data from OneDrive, SharePoint, and Teams within seconds of ingestion during a routine summarization task. The agent was authenticated. The instruction source was not. Microsoft patched it. In January 2026, a similar prompt injection in Copilot Studio (CVE-2026-21520) was patched, and data exfiltrated anyway. These are not model failures. They are authorization architecture failures.
The fix requires instruction-source authentication and scope re-evaluation before execution, not better semantic filtering alone. A pre-execution gate should evaluate three questions: Where did the instruction originate? Is that origin authenticated under the trust model governing this run? Does the requested action remain within the active scope contract given that origin?
«»
Memory Manipulation and the Problem That Survives the Session
Traditional identity compromise was naturally bounded by the session. Agentic systems weaken that assumption in a way that changes the governance problem materially.
Agents preserve operational state across time. That state may live in explicit memory stores, long-lived threads, retrieval caches, configuration files, task queues, or semi-persistent behavioral preferences. Whatever the implementation, the security consequence is the same: one successful compromise can alter the starting conditions of future runs.
Memory manipulation and context poisoning are therefore not just influence operations. They are persistence mechanisms.
Microsoft’s February 2026 threat intelligence documented adversaries planting durable manipulative instructions in assistant memory to alter future recommendations. Palo Alto Networks Unit 42’s October 2025 research demonstrated indirect prompt injection that successfully poisoned an agent’s long-term memory in a proof-of-concept against Amazon Bedrock infrastructure altering future behavior across sessions without re-exploitation. Both are vendor-sourced, so they carry the commercial context that comes with that; the architectural pattern they illustrate is still not vendor-specific.
The containment consequence is reasonably straightforward. Persistent state that can shape future privileged behavior must be governed more like executable policy or mutable configuration than like inert user content. That means versioning, lineage, provenance checks, rollback capability, and anomaly-triggered suspension when privileged behavior deviates from approved state lineage. An agent memory entry that materially changes tool use is not merely a note. It is, as the brief puts it, an authorization-adjacent artifact.
Session isolation remains necessary. It is no longer sufficient.
«»
Privilege Escalation Through Agent Hierarchies
Multi-agent architecture makes agent systems useful. It also makes them dangerous in a very specific way that most current implementations have not accounted for.
A parent orchestrator agent receives a task, decomposes it, and delegates subtasks to child agents with more specialized tool access or narrower operating contexts. In principle, that architecture should improve control, each child receives only the authority required for its subtask. In practice, many implementations do not perform explicit authority attenuation at each delegation step. They pass execution power down the hierarchy more loosely than the governance model assumes.
Every delegation step should compute a scope intersection, not a scope inheritance. The child should receive at most the subset of still-valid parent authority explicitly required for the subtask, for the lifetime of that subtask, under a preserved actor chain and attached contract version. Where that rule is absent, a compromised child agent does not gain only its nominal access. It gains what the parent can cause it to inherit.
OWASP Agentic AI Top 10 2026 (ASI03) identifies this directly: manipulating delegation chains, role inheritance, and control flows is a primary attack vector in the agent identity category. The telemetry is what makes this particularly problematic where the downstream system sees a valid token, the call appears authorized, the credential is entirely legitimate. What is violated is not the authentication layer. It is the intended authority transformation across the delegation chain.
The prevention pattern is architectural, not procedural: parent-to-child delegation must use explicit token transformation (RFC 8693) rather than token reuse; delegated scope must be mechanically attenuated; child runs must not mint fresh standing authority for themselves outside the issuing control plane. Without that, ordinary logging cannot surface the violation. The audit trail shows valid delegation. It cannot show the scope boundary that was violated.
«»
RAG Retrieval Is a Governed Access Surface, Not a Knowledge Feature
Retrieval-Augmented Generation (RAG) is widely discussed as a grounding mechanism for reducing hallucination. In adversarial terms, it is also a data-reach mechanism and in many enterprise deployments, a poorly governed one.
Enterprise retrieval corpora frequently contain material that was never intended to become machine-retrievable in a broadly usable way: runbooks with embedded secrets, configuration files, connection strings, internal endpoints, service-account details, procedural instructions that materially lower the cost of exploitation. Documents may be classified at rest and still become dangerous once indexed semantically.
The attack has two operational forms. In the first, an adversary issues queries semantically proximate to credential patterns including API authentication procedures, service account configuration guides, database connection string formats and the retrieval system surfaces runbooks and configuration documents ingested without classification review. In the second, a prompt-injected agent is directed to retrieve and exfiltrate content matching specific semantic patterns, using the agent’s legitimate retrieval authority as the exfiltration channel. The retrieval operation is not anomalous. The credential scope includes retrieval. The anomaly is the instruction source and the destination, neither of which retrieval-layer monitoring typically evaluates.
NIST SP 800-228 (June 2025) reinforces this directly: generative agents are increasingly exposed as APIs, frequently have access to business-sensitive operational data, and have already been targeted by prompt injection attacks specifically to exfiltrate data. That is not a generic risk statement. It is an operational description of an attack that has already run in production.
The standard failure is to stop classification at ingest. An organization scrubs some obvious secrets, indexes the rest, and treats retrieval as safe because the knowledge base is internal. That logic fails twice: ingest-time controls are rarely perfect, and even if document-level permissions are respected, retrieval can still surface content whose semantic relevance far exceeds its authorization relevance.
An agent’s scope contract should specify which indexed corpora, which document classes, and which data classification tiers are valid for the current run. Retrieval is not just a knowledge feature. It is a governed access surface.
«»
The Speed Asymmetry Removes the Last Excuse
The defensive problem is not only that these attacks are hard to interpret. It is that they unfold at a speed human review cannot reliably contain.
CrowdStrike’s 2026 Global Threat Report documents that the average eCrime breakout time, elapsed time from initial access to lateral movement, fell to 29 minutes in 2025, a 65% increase in adversary speed year-over-year. The fastest recorded breakout was 27 seconds. In one documented intrusion, data exfiltration began within four minutes of initial access. AI-enabled adversaries increased operations by 89% year-over-year. These are not benchmarks for exceptional adversaries; they are measurements of documented incident sequences across the threat landscape.
Enterprises are still tempted to compensate for incomplete control design with supervisory review; someone will inspect the logs, a security analyst will approve higher-risk actions, a platform owner will investigate anomalies before containment. That model already struggles in ordinary identity-centric attacks. It is structurally insufficient when an agent can move through several legitimate systems before the alert is even triaged.
The brief’s framing here is pretty clear: pre-authorization is the operationally critical term. A circuit breaker that requires human approval before triggering is not a circuit breaker. It is a notification that will arrive after the damage is done. The response components including suspension, scope revocation, and credential invalidation must be authorized to act before an incident occurs, under conditions specified in the scope contract and behavioral policy, without requiring a human decision in the detection window.
That is not aggressive automation. It is the architectural consequence of a 29-minute average breakout time.
«»
Steeply Sloped Acceleration
Stepping back from the brief for a moment to note where all of this sits in the broader landscape: the governance gap for non-human identities is not a niche concern.
78% of organizations currently lack formal policies for creating or removing AI identities. 92% report they are not confident their legacy IAM tools can effectively manage AI and NHI risks. The Huntress 2026 data breach report identified NHI compromise as the fastest-growing attack vector in enterprise infrastructure. 48% of cybersecurity professionals identify agentic AI and autonomous systems as the top attack vector heading into 2026.
And NIST has now launched an AI Agent Standards Initiative (February 2026), recognizing that the governance vocabulary for this principal class is still being built in real time.
It’s equally clear that the industry is not going to slow deployment to wait for the governance infrastructure to catch up. That is pretty much always how this goes. The relevant question is not whether to deploy agents, it is whether the security and identity architecture for agents is built before adversaries systematically map the gap, or after. The 14 MITRE ATLAS agent-specific techniques suggest adversaries have already started the mapping.
«»
What the Brief Provides
The full technical brief (attached) goes significantly deeper than this summary. It includes:
A precise mapping of every MITRE ATLAS agent technique to the named identity component it targets and the governance absence it exploits, with required enforcement actions for each. Three attack scenarios abstracted from documented CrowdStrike adversary tradecraft, each tracing from initial access through the governance failure that made the attack viable, to the architectural control that would have broken the chain. A seven-dimension adversarial exposure assessment framework that can be applied against a production environment, scored 0, 1, or 2 per dimension, with immediate action guidance at each score level. Specific calls to NIST SP 800-228, OWASP LLM Top 10 2025, OWASP Agentic AI Top 10 2026, RFC 8693, RFC 8705, and Anthropic’s April 2026 Alignment Risk Update for Claude Mythos Preview.
Machine identity governance and AI-native defense are not separate programs. They are the same architecture viewed from two directions; one building the governed principal, the other building the defenses that protect it.
note- The paper attached to this article originally appeared in the Cognitive Sprawl’s “Defending the Agentic Enterprise” subscribers section. Given the current security landscape I wanted to make it available to the general Substack audience.
«Attached Brief»
«»
««»»
Select Sources:
Shaughnessy, R.J. “The Adversarial Agent: How Threat Actors Exploit the Non-Human Identity Gap.” Machine Identity Series, Part 3, April 14, 2026. (attached)
CrowdStrike. “2026 Global Threat Report: Evasive by Design.” February 24, 2026.
OWASP GenAI Security Project. “OWASP Top 10 for Agentic Applications for 2026.” December 2025.
OWASP GenAI Security Project. “OWASP Top 10 for LLM Applications 2025.” November 2024.
NIST. “Guidelines for API Protection for Cloud-Native Systems (SP 800-228).” June 2025.